La forma en que la IA está moldeando el futuro de la infraestructura y las plataformas de datos en 2024
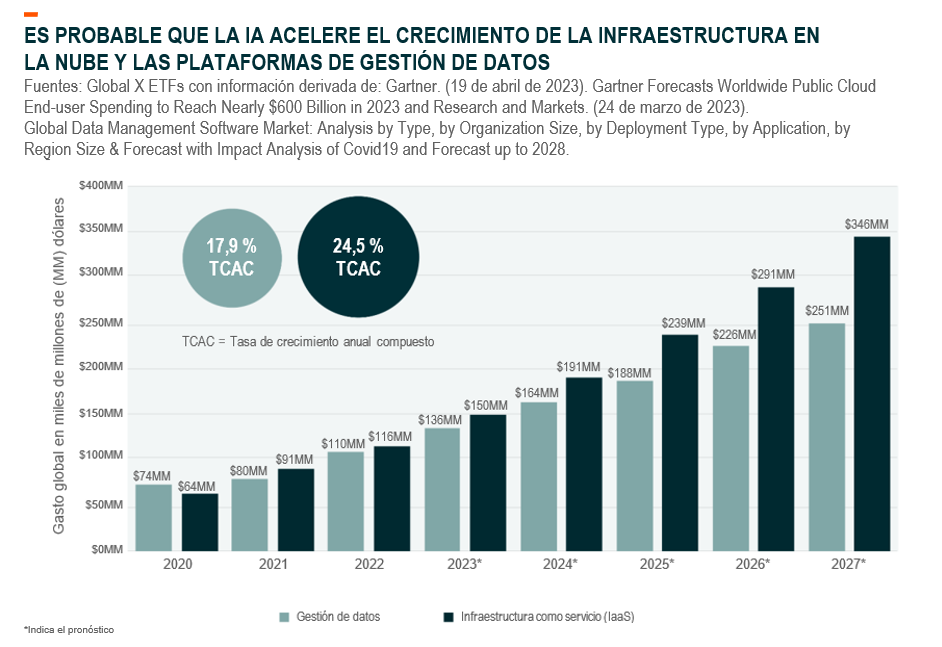
Los datos son el combustible de la IA. Y cuantos más datos obtiene la IA, mayor es el efecto de bola de nieve de datos que crea. Desde nuestro punto de vista, la cadena de valor involucrada en el procesamiento y manejo de todos esos datos no debe pasarse por alto. La creciente demanda comercial de soluciones de IA generativa crea demanda de software y hardware especializados para respaldar la recopilación, el almacenamiento y el procesamiento de cantidades masivas de datos. Además, a medida que los modelos de IA generativa se entrenan con datos internos y privados, aumentan las necesidades de soluciones de acceso a datos seguras y eficientes, soluciones de gobernanza e infraestructura de computación en la nube auxiliar.
En este artículo, destacamos cómo la IA generativa crea oportunidades de crecimiento significativas para las empresas en los mercados de infraestructura en la nube y gestión de datos.
CONCLUSIONES CLAVE
- La creciente demanda de soluciones de IA generativa requiere inversiones sustanciales por parte de las empresas en soluciones de almacenamiento, infraestructura y gestión de datos, además del hardware.
- Es probable que los datos sintéticos y los datos generados por los agentes de IA aumenten significativamente junto con los datos del mundo real.
- Esperamos que las empresas que proporcionan soluciones de gestión de datos e infraestructura en la nube crezcan en magnitud como medios que permitirán a los inversionistas obtener una exposición convincente al tema de la inteligencia artificial.
Se buscan datos de alta calidad para la IA
Los modelos de IA generativa se entrenan en grandes conjuntos de datos de información estructurada y no estructurada, lo que forma la base de su capacidad para razonar y responder preguntas. Para tener una perspectiva de esto, GPT-3 de Open AI se entrenó con un conjunto de datos de 45 terabytes (TB) que combinó varias fuentes de datos de la web abierta, incluidos Common Crawl (60 %), WebText2 (22 %), Booksl (8 %), Books2 (8 %) y Wikipedia (3 %)1.
La creciente adopción de la IA y el aumento de las inversiones empresariales deberían estimular esfuerzos de entrenamiento adicionales por parte de desarrolladores y empresas de tecnología en modelos fundamentales. El rendimiento del modelo escala con el tamaño y la calidad de los datos de entrenamiento de entrada, por lo que a medida que crece la implementación de IA, también lo hará la demanda de fuentes de datos de alta calidad2. Sin embargo, los datos del mundo real solo pueden llevar estos modelos hasta este punto. Debido a que los datos del mundo real pueden ser limitados y escasos, es probable que las fuentes alternativas de información, como los datos privados y los datos sintéticos, se vuelvan más prominentes en el desarrollo de la IA3.
Los datos privados se refieren a información y datos empresariales de propiedad exclusiva que pueden utilizarse para capacitar modelos destinados a casos de uso interno específicos. Debido al enfoque limitado de los activos de datos privados, estos modelos pueden ser más eficientes y útiles que los modelos listos para usar. Por ejemplo, el modelo de lenguaje grande de 50 000 millones de parámetros de Bloomberg, entrenado con conjuntos de datos financieros, supera a los modelos abiertos de tamaño similar en tareas de procesamiento de lenguaje natural (natural language processing, NLP) financiero4. Esperamos que surjan ejemplos similares en el área sanitaria, logística, de fabricación, de tecnología de defensa, de ciberseguridad y otros sectores.
Los datos sintéticos son información fabricada artificialmente a través de algoritmos en lugar de a partir de hechos del mundo real. Estos datos pueden diseñarse para que parezcan casi perfectos. En la mayoría de los casos, los datos sintéticos se utilizan para completar conjuntos de datos del mundo real, al reemplazar datos históricos que ya no son pertinentes o a veces inaccesibles. También es rentable, no implica preocupaciones de privacidad y está perfectamente anotada. Para 2024, se espera que casi el 60 % de los datos utilizados para desarrollar IA y análisis sean sintéticos5.
Se necesitan más inversiones en hardware y software
El entrenamiento y el desarrollo de nuevos modelos, la integración de datos del mundo real para el razonamiento y la evaluación basados en IA, y el uso de datos privados y datos sintéticos requieren inversiones integrales en infraestructura de datos.
El aumento de uso y procesamiento de datos a medida que la huella de la IA se expande crea principalmente una necesidad de almacenamiento y memoria del centro de datos. Con las vacantes de centros de datos que ya están en mínimos históricos, la construcción de una nueva capacidad de centros de datos para respaldar la demanda de cargas de trabajo centradas en la IA está siendo testigo de un repunte6. Miles de millones de dólares en inversiones de capital de hiperescaladores en la nube como Microsoft, Amazon, Google, gigantes de centros de datos como Equinix, así como empresas de capital privado están siendo catalizadas hacia centros de datos de IA de propósitos específicos7.
El almacenamiento para el procesamiento de IA también debe adaptarse al acceso a datos de baja latencia y en tiempo real, por lo que los proveedores de soluciones de almacenamiento están expandiendo sus carteras. Por ejemplo, Seagate Technologies lanzó recientemente una plataforma de almacenamiento de 24TB de IA Seagate SkyHawk, que está diseñada para el almacenamiento de imágenes y videos en el perímetro de las aplicaciones de IA8. Junto con las instalaciones de servidores de IA, existe la demanda de memoria de gran ancho de banda (high-bandwidth memory, HBM), que está diseñada para un consumo de energía bajo y carriles de comunicación ultraanchos9. Empresas como Samsung y HK Hynix dominan este mercado10.
Por el lado de los software de datos, las empresas probablemente tendrán que invertir en soluciones de plataforma y construir canales y otra infraestructura necesaria que permita a los modelos interactuar con usuarios y sistemas. Es posible que las empresas tradicionales también deban limpiar, procesar y remodelar sus activos de datos existentes para prepararlos para el entrenamiento y la inferencia de IA. Los servicios de base de datos de vectores, como los proporcionados por MongoDB y cada vez más por titulares como Oracle, son sistemas de almacenamiento especializados optimizados para almacenar y buscar a través de datos de vectores. Los modelos de IA generativos utilizan tecnología de búsqueda de vectores para analizar los extensos depósitos de información mediante la identificación de puntos de datos pertinentes basados en sus vectores, que son representaciones numéricas en un contenido multidimensional.
Es probable que los agentes de IA que interactúan entre sí se vuelvan algo común, lo que requiere integraciones de sistemas únicos que brinden espacio para la innovación a los proveedores de soluciones de datos. Además, la captura de datos sin errores de aplicaciones de IA del mundo real, incluidos dispositivos de Internet de las cosas, robótica, drones y otros sistemas mecánicos, requiere inversiones en mejores configuraciones de detección, procesadores perimetrales y redes perimetrales, así como software asociado y plataformas de datos.
Estas inversiones se extienden a estrategias de nube más amplias a medida que las empresas configuran sus operaciones de TI para que sean compatibles con los sistemas de nube públicos y privados. Las agendas de transformación digital existentes deben acelerarse, en beneficio de proveedores de servicios de infraestructura informática basados en la nube como Microsoft, Amazon Web Services y Google Cloud, así como de grandes proveedores de plataformas como ServiceNow11,12,13,14.
Conclusión: infraestructura esencial para el efecto de bola de nieve de datos de la lA
Los modelos de IA generativos necesitan acceso a datos de alta calidad, en tiempo real y de propiedad exclusiva para cumplir con su vasto potencial. La construcción del sector público y privado de las plataformas de gestión de datos e infraestructura necesarias para lograrlo posiciona a las empresas que venden la infraestructura en la nube, los hardware de almacenamiento, las bases de datos, los depósitos de datos, las herramientas de transmisión de datos y más para beneficiarse. Y dentro de esos productos, creemos que hay oportunidades atractivas para que los inversionistas saquen provecho del crecimiento de la IA.